from Imagine to CUDA
来源:百度文库 编辑:超级军网 时间:2024/04/19 14:59:11

Last updated Sept 2, 2008
Bill Dally is the Willard R. and Inez Kerr Bell Professor of Computer Science and Electrical Engineering and Chairman of the Computer Science Department at Stanford University. He is a member of the Computer Systems Laboratory, leads the Concurrent VLSI Architecture Group, and teaches courses on Computer Architecture, Computer Design, and VLSI Design. He is a Fellow of the American Academy of Arts & Sciences , a Fellow of the IEEE, a Fellow of the ACM, received the ACM Maurice Wilkes Award in 2000, and the IEEE Seymour Cray Award in 2004.
Before coming to Stanford, Bill was a Professor in the department of Electrical Engineering and Computer Science at MIT .
Current Projects
ELM: The Efficient Low-Power Microprocessor
We are developing a programmable architecture that is easily programmable in a high-level language ("C") and at the same time has performance per unit power competitive with hard-wired logic, and 20-30x better than conventional embedded RISC processors. This power savings is achieved by using more efficient mechanisms for instruction supply, based on compiler managed instruction registers, and data supply, using a deeper register hierarchy and indexable registers.
On-chip Interconnection Networks
As CMPs and SoCs scale to include large numbers of cores and other modules, the on-chip network or NoC that connects them becomes a critical systems component. We are developing enabling technology for on-chip networks including network topologies, flow control mechanisms, and router organizations. For example, our flattened butterfly topology offers both lower latency and substantially reduced power compared to conventional on-chip mesh or ring networks.
Sequoia: Programming the Memory Hierarchy
Sequoia is a programming language that is designed to facilitate the development of memory hierarchy aware parallel programs that remain portable across modern machines with different memory hierarchy configurations. Sequoia abstractly exposes hierarchical memory in the programming model and provides language mechanisms to describe communication vertically through the machine and to localize computation to particular memory locations within the machine. A complete Sequoia programming system has been implemented, including a compiler and runtime systems for both Cell processors and distributed memory clusters, that delivers efficient performance running Sequoia programs on both of these platforms. An alpha version of this programming system will soon be made public.
Scalable Network Fabrics
We are developing architectures and technologies to enable large, scalable high-performance interconnection networks to be used in parallel computers, network switches and routers, and high-performance I/O systems. Recent results include the development of a hierarchical network topology that makes efficient use of a combination of electrical and optical links, a locality-preserving randomized oblivious routing algorithm, a method for scheduling constrained crossbar switches, new speculative and reservation-based flow control methods, and a method for computing the worst-case traffic pattern for any oblivious routing function.
Recent Projects
Streaming Supercomputer
We are developing a streaming supercomputer (SS) that is scalable from a single-chip to thousands of chips that we estimate will achieve an order of magnitude or more improvement in the performance per unit cost on a wide range of demanding numerical computations compared to conventional cluster-based supercomputers. The SS uses a combination of stream processing with a high-performance network to access a globally shared memory to achieve this goal.
Imagine: A High-Performance Image and Signal Processor
Imagine is a programmable signal and image processor that provides the performance and performance density of a special-purpose processor. Imagine achieves a peak performance of 20GFLOPS (single-precision floating point) and 40GOPS (16-bit fixed point) and sustains over 12GFLOPS and 20GOPS on key signal processing benchmarks. Imagine sustains a power efficiency of 3.7GFLOPS/W on these same benchmarks, a factor of 20 better than the most efficient conventional signal processors.
Smart Memories
We are investigating combined processor/memory architectures that are best able to exploit 2009 semiconductor technologies. We envision these architectures being composed of 10s to 100s of processors and memory banks on a single semiconductor chip. Our research addresses the design of the processors and memories, the architecture of the interconnection network that ties them together, and mechanisms to simplify programming of such machines.
High-Speed Signalling
We are developing methods and circuits that stretch the performance bounds of electrical signalling between chips, boards, and cabinets in a digital system. A prototype 0.25um 4Gb/s CMOS transceiver has been developed, dissipating only 130mW, amenable for large scale integration. Future chips include a a 20Gb/s 0.13um CMOS transceiver.
The M-Machine
Is an experimental parallel computer that demonstrated highly-efficient mechanisms for parallelism including two-level multithreading, efficient network interfaces, fast communication and synchronization, and support for efficient shared memory protocols.
The Reliable Router
is a high-performance multicomputer router that demonstrates new technologies ranging from architecture to circuit design. At the architecture level the router uses a novel adaptive routing algorithm, a link-level retry protocol, and a unique token protocol. Together the two protocols greatly reduce the cost of providing reliable, exactly-once end-to-end communication. At the circuit level the router demonstrates the latest version of our simultaneous bidirectional pads and a new method for plesiochronous synchronization.
The J-Machine
is an experimental parallel computer, in operation since July 1991, that demonstrates mechanisms that greatly reduce the overhead involved in inter-processor interaction.
Companies
Bill has played a key role in founding several companies including:
Stream Processors Inc.(2004-present)
to commercialize stream processors for embedded applications.
Velio Communications. (CTO 1999-2003)
Velio pioneered high-speed I/O circuits and applied this technology to integrated TDM and packet switching chips. Velio's I/O technology was acquired by Rambus and Velio itself was acquired by LSI Logic.
Avici Systems, Inc.(1997-present)
Manufactures core Internet routers with industry-leading scalability and reliability.
Bill has also worked with Cray since 1989 on the development of many of their supercomputers including the T3D and T3E. He is currently collaborating with Cray on their HPCS effort.
Selected Publications
* William Dally et al. "Stream Processors: Programmability with Efficiency" ACM Queue, March 2004, pp. 52-62.
* William Dally et al., "Merrimac: Supercomputing with Streams" Supercomputing 2003
* William J. Dally and Brian Towles, Principles and Practices of Interconnection Networks Morgan Kaufmann, 2004
* William J. Dally and John W. Poulton, Digital Systems Engineering, Cambridge University Press, 1998
* Fillo, Marco, Keckler, Stephen W., Dally, William J., Carter, Nicholas P., Chang, Andrew, Gurevich, Yevgeny, and Lee, Whay S., "The M-Machine Multicomputer" , International Journal of Parallel Programming - Special Issue on Instruction-Level Parallel Processing Part II . Vol 25, No 3, 1997 pp 183-212.
* Dally, William J., Chang, Andrew., Chien, Andrew., Fiske, Stuart., Horwat, Waldemar., Keen, John., Lethin, Richard., Noakes, Michael., Nuth, Peter., Spertus, Ellen., Wallach, Deborah., and Wills, D. Scott.
"The J-Machine" . Retrospective in 25 Years of the International Symposia on Computer Architecture - Selected Papers. pp 54-58.
* William J. Dally, Virtual Channel Flow Control, IEEE Transactions on Parallel and Distributed Systems March, 1992, pp. 194-205.
A more complete list of publications can be found at the CVA group publications page
Recent Talks, Etc...
* Low-Power Architecture, ISSCC 2005, February 7, 2005, San Francisco, California, USA.
* VLSI Architecture: Past, Present, and Future
Courses
* CS 99S -- The Coming Revolution in Computer Architecture (freshman seminar)
* EE108A Digital Systems I
* EE271 Introduction to VLSI Systems
* EE273 -- Digital Systems Engineering
* EE282 Computer Architecture and Organization
* EE482a--Advanced Computer Organization: Processor Microarchitecture
* EE482b--Advanced Computer Organization: Interconnection Networks
* 6.823 Computer System Architecture
* 6.845 Concurrent VLSI Architecture
* 6.915 Digital Systems Engineering
CVA People
William J. Dally
<dally "at" stanford "dot" edu>
Stanford University
Computer Systems Laboratory
Gates Room 301
Stanford, CA 94305
(650) 725-8945
FAX: (650) 725-6949William J. Dally
Last updated Sept 2, 2008
Bill Dally is the Willard R. and Inez Kerr Bell Professor of Computer Science and Electrical Engineering and Chairman of the Computer Science Department at Stanford University. He is a member of the Computer Systems Laboratory, leads the Concurrent VLSI Architecture Group, and teaches courses on Computer Architecture, Computer Design, and VLSI Design. He is a Fellow of the American Academy of Arts & Sciences , a Fellow of the IEEE, a Fellow of the ACM, received the ACM Maurice Wilkes Award in 2000, and the IEEE Seymour Cray Award in 2004.
Before coming to Stanford, Bill was a Professor in the department of Electrical Engineering and Computer Science at MIT .
Current Projects
ELM: The Efficient Low-Power Microprocessor
We are developing a programmable architecture that is easily programmable in a high-level language ("C") and at the same time has performance per unit power competitive with hard-wired logic, and 20-30x better than conventional embedded RISC processors. This power savings is achieved by using more efficient mechanisms for instruction supply, based on compiler managed instruction registers, and data supply, using a deeper register hierarchy and indexable registers.
On-chip Interconnection Networks
As CMPs and SoCs scale to include large numbers of cores and other modules, the on-chip network or NoC that connects them becomes a critical systems component. We are developing enabling technology for on-chip networks including network topologies, flow control mechanisms, and router organizations. For example, our flattened butterfly topology offers both lower latency and substantially reduced power compared to conventional on-chip mesh or ring networks.
Sequoia: Programming the Memory Hierarchy
Sequoia is a programming language that is designed to facilitate the development of memory hierarchy aware parallel programs that remain portable across modern machines with different memory hierarchy configurations. Sequoia abstractly exposes hierarchical memory in the programming model and provides language mechanisms to describe communication vertically through the machine and to localize computation to particular memory locations within the machine. A complete Sequoia programming system has been implemented, including a compiler and runtime systems for both Cell processors and distributed memory clusters, that delivers efficient performance running Sequoia programs on both of these platforms. An alpha version of this programming system will soon be made public.
Scalable Network Fabrics
We are developing architectures and technologies to enable large, scalable high-performance interconnection networks to be used in parallel computers, network switches and routers, and high-performance I/O systems. Recent results include the development of a hierarchical network topology that makes efficient use of a combination of electrical and optical links, a locality-preserving randomized oblivious routing algorithm, a method for scheduling constrained crossbar switches, new speculative and reservation-based flow control methods, and a method for computing the worst-case traffic pattern for any oblivious routing function.
Recent Projects
Streaming Supercomputer
We are developing a streaming supercomputer (SS) that is scalable from a single-chip to thousands of chips that we estimate will achieve an order of magnitude or more improvement in the performance per unit cost on a wide range of demanding numerical computations compared to conventional cluster-based supercomputers. The SS uses a combination of stream processing with a high-performance network to access a globally shared memory to achieve this goal.
Imagine: A High-Performance Image and Signal Processor
Imagine is a programmable signal and image processor that provides the performance and performance density of a special-purpose processor. Imagine achieves a peak performance of 20GFLOPS (single-precision floating point) and 40GOPS (16-bit fixed point) and sustains over 12GFLOPS and 20GOPS on key signal processing benchmarks. Imagine sustains a power efficiency of 3.7GFLOPS/W on these same benchmarks, a factor of 20 better than the most efficient conventional signal processors.
Smart Memories
We are investigating combined processor/memory architectures that are best able to exploit 2009 semiconductor technologies. We envision these architectures being composed of 10s to 100s of processors and memory banks on a single semiconductor chip. Our research addresses the design of the processors and memories, the architecture of the interconnection network that ties them together, and mechanisms to simplify programming of such machines.
High-Speed Signalling
We are developing methods and circuits that stretch the performance bounds of electrical signalling between chips, boards, and cabinets in a digital system. A prototype 0.25um 4Gb/s CMOS transceiver has been developed, dissipating only 130mW, amenable for large scale integration. Future chips include a a 20Gb/s 0.13um CMOS transceiver.
The M-Machine
Is an experimental parallel computer that demonstrated highly-efficient mechanisms for parallelism including two-level multithreading, efficient network interfaces, fast communication and synchronization, and support for efficient shared memory protocols.
The Reliable Router
is a high-performance multicomputer router that demonstrates new technologies ranging from architecture to circuit design. At the architecture level the router uses a novel adaptive routing algorithm, a link-level retry protocol, and a unique token protocol. Together the two protocols greatly reduce the cost of providing reliable, exactly-once end-to-end communication. At the circuit level the router demonstrates the latest version of our simultaneous bidirectional pads and a new method for plesiochronous synchronization.
The J-Machine
is an experimental parallel computer, in operation since July 1991, that demonstrates mechanisms that greatly reduce the overhead involved in inter-processor interaction.
Companies
Bill has played a key role in founding several companies including:
Stream Processors Inc.(2004-present)
to commercialize stream processors for embedded applications.
Velio Communications. (CTO 1999-2003)
Velio pioneered high-speed I/O circuits and applied this technology to integrated TDM and packet switching chips. Velio's I/O technology was acquired by Rambus and Velio itself was acquired by LSI Logic.
Avici Systems, Inc.(1997-present)
Manufactures core Internet routers with industry-leading scalability and reliability.
Bill has also worked with Cray since 1989 on the development of many of their supercomputers including the T3D and T3E. He is currently collaborating with Cray on their HPCS effort.
Selected Publications
* William Dally et al. "Stream Processors: Programmability with Efficiency" ACM Queue, March 2004, pp. 52-62.
* William Dally et al., "Merrimac: Supercomputing with Streams" Supercomputing 2003
* William J. Dally and Brian Towles, Principles and Practices of Interconnection Networks Morgan Kaufmann, 2004
* William J. Dally and John W. Poulton, Digital Systems Engineering, Cambridge University Press, 1998
* Fillo, Marco, Keckler, Stephen W., Dally, William J., Carter, Nicholas P., Chang, Andrew, Gurevich, Yevgeny, and Lee, Whay S., "The M-Machine Multicomputer" , International Journal of Parallel Programming - Special Issue on Instruction-Level Parallel Processing Part II . Vol 25, No 3, 1997 pp 183-212.
* Dally, William J., Chang, Andrew., Chien, Andrew., Fiske, Stuart., Horwat, Waldemar., Keen, John., Lethin, Richard., Noakes, Michael., Nuth, Peter., Spertus, Ellen., Wallach, Deborah., and Wills, D. Scott.
"The J-Machine" . Retrospective in 25 Years of the International Symposia on Computer Architecture - Selected Papers. pp 54-58.
* William J. Dally, Virtual Channel Flow Control, IEEE Transactions on Parallel and Distributed Systems March, 1992, pp. 194-205.
A more complete list of publications can be found at the CVA group publications page
Recent Talks, Etc...
* Low-Power Architecture, ISSCC 2005, February 7, 2005, San Francisco, California, USA.
* VLSI Architecture: Past, Present, and Future
Courses
* CS 99S -- The Coming Revolution in Computer Architecture (freshman seminar)
* EE108A Digital Systems I
* EE271 Introduction to VLSI Systems
* EE273 -- Digital Systems Engineering
* EE282 Computer Architecture and Organization
* EE482a--Advanced Computer Organization: Processor Microarchitecture
* EE482b--Advanced Computer Organization: Interconnection Networks
* 6.823 Computer System Architecture
* 6.845 Concurrent VLSI Architecture
* 6.915 Digital Systems Engineering
CVA People
William J. Dally
<dally "at" stanford "dot" edu>
Stanford University
Computer Systems Laboratory
Gates Room 301
Stanford, CA 94305
(650) 725-8945
FAX: (650) 725-6949


Implementation Overview

On April 9th, 2002, first samples of a prototype Imagine stream processor were received at Stanford. A wafer containing 93 Imagine die is shown to the left. (Click on the picture for a larger view).
The Imagine stream processor is a 16mm x 16mm, 21 million transistor chip implemented by a collaboration between Stanford Unversity and Texas Instruments (TI) in a 1.5V 0.15 micron process with five layers of aluminum metal. Stanford designed the architecture, logic, and did the floorplanning and cell placement. TI completed the layout and layout verification.
Building a prototype Imagine processor contributed in three key ways to the overall project. First, many things were learned about the stream architecture by implementing Imagine in VLSI. Second, having prototype processors available enables real-time application and tool development which is not possible on hardware simulators. Finally, building a prototype Imagine provides a proof-of-concept to the VLSI feasibility of the processor and allows architectural studies to be based on results from actual silicon.
ScheduleThe Imagine implementation effort began in autumn, 1998. At its peak, the Stanford team working on design and verification six graduate students working on design and verification. The history of the Imagine implementation is shown below. In total, Stanford expended 11 person-years of work on the logic design, floorplanning, and placement of the Imagine processor. |
Design MethodologyImagine was designed in a standard cell technology using theTI-ASIC design methodology. Detailed information on the designmethodology can be found in "VLSI Design and Verification of the Imagine Processor". |
| Die Photo
|
Implementation Overview
On April 9th, 2002, first samples of a prototype Imagine stream processor were received at Stanford. A wafer containing 93 Imagine die is shown to the left. (Click on the picture for a larger view).
The Imagine stream processor is a 16mm x 16mm, 21 million transistor chip implemented by a collaboration between Stanford Unversity and Texas Instruments (TI) in a 1.5V 0.15 micron process with five layers of aluminum metal. Stanford designed the architecture, logic, and did the floorplanning and cell placement. TI completed the layout and layout verification.
Building a prototype Imagine processor contributed in three key ways to the overall project. First, many things were learned about the stream architecture by implementing Imagine in VLSI. Second, having prototype processors available enables real-time application and tool development which is not possible on hardware simulators. Finally, building a prototype Imagine provides a proof-of-concept to the VLSI feasibility of the processor and allows architectural studies to be based on results from actual silicon.
Schedule
The Imagine implementation effort began in autumn, 1998. At its peak, the Stanford team working on design and verification six graduate students working on design and verification. The history of the Imagine implementation is shown below. In total, Stanford expended 11 person-years of work on the logic design, floorplanning, and placement of the Imagine processor.
- 11/1998: Logic design commenced (team consists of one student writing the behavioral RTL for an ALU cluster)
- 11/2000: First trial placement of an ALU cluster completed
- 12/2000: Behavioral RTL completed and functionally verified (team has grown to five graduate students)
- 08/2001: Final placement and floorplanning completed by Stanford, and design is handed off to TI for layout and layout verification
- 02/2002: Imagine parts enter a TI fab (part number F741749)
- 04/2002: Stanford receives Imagine parts
- 06/2002: First full application succesfully run in the lab
Design Methodology
Imagine was designed in a standard cell technology using theTI-ASIC design methodology. Detailed information on the designmethodology can be found in "VLSI Design and Verification of the Imagine Processor".
Die Photo
The final cell placement and die photo of the Imagine chip are shown below.
Figure 1. Final cell placement of Imagine (click image for larger view)

Figure 2. Die Photo of Imagine (click image for larger view)
Depth Extraction
|


Depth Extraction
In stereo depth extraction, two cameras are located a fixed horizontaldistance apart, on the same vertical and depth axes. A computer isemployed to determine the distance of objects from the plane of the cameras;this task consumes substantial computing resources as each pixel of the finaldepth image requires two convolution operations.
Imagine sustains 12.1 GOPS for Stereo depth extraction, which allowsextraction of 212 frames per second of 320x240, 8-bit grayscale images.
Figure 1 shows the source images from a pair of (simulated) cameras. Figure 2 is the depth map produced by the depth extraction.

Figure 1: Left and right camera images
Figure 2: Resulting depth map
Depth extraction has applications in the extraction of 3-Dmodels of real objects. These models are useful for purposes which requirereal-time 3-D data, such as tele-presence communications.
Cycle-accurate simulations of Imagine show the high performance that can be achieved on MPEG-2 compression.
Raw speed measurements are:
- For 360x288 images, 24-bit: 350 frames per second
- For 720x480 images, 24-bit: 105 frames per second
Overall, the Imagine achieves 18.3 GOPS, with a power efficiency of 8.3 GOPS/W.
那块板子真设计的失败,都飞线了,贴软文没有意义,没有多少有价值的信息,CUDA的意义其实主要还是在C语言编译器上
那块板子真设计的失败,都飞线了,贴软文没有意义,没有多少有价值的信息,CUDA的意义其实主要还是在C语言编译器上
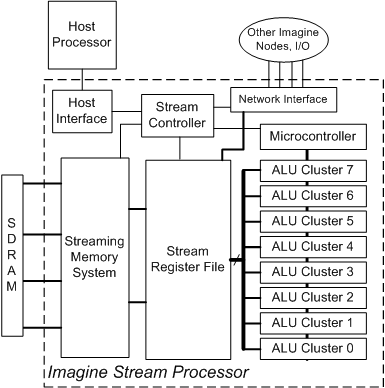
The host interface allows an Imagine processor to be mapped into the host processor's address space, so the host processor can read and write Imagine memory. The host processor also executes programs that issue the appropriate stream-level instructions to the Imagine processor. These instructions are written to special memory mapped locations in the host interface.